原标题:唐驳虎:憋了5年美国超算重超中国,但只能秀半年
凤凰新闻客户端主笔 唐驳虎
周末最大的科技新闻,应该是美国超级计算机重夺世界第一,速度超过了中国“神威”60%。
笔者也正好借此机会向公众介绍一下超级计算机领域激烈的中美竞争。而且这应该是真正最完整和最通俗的解读了。
【美国已经落后甚至被甩开了5年】
这将是自2013年6月以来,美国首次登上超级计算机的榜首,当时它被中国广州的天河二号夺去了第一名。到2016年,中国无锡的神威-太湖之光,又以3倍的优势大幅度刷新记录,继续为中国把持着榜单首位。
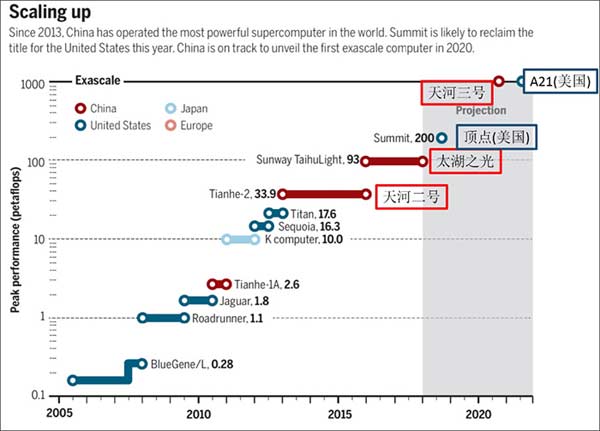
在上一轮,也就是去年年底的全球超级计算机TOP500排行上,美国的最高排位已经被瑞士和日本挤到了第五位。

而在TOP500总榜单中,中国系统总数为202台,占比超过四成位居第一。美国只剩143台。中国在总体算力上也超过了美国。在TOP500的总算力中,中国占了35.4%,美国只有29.6%。
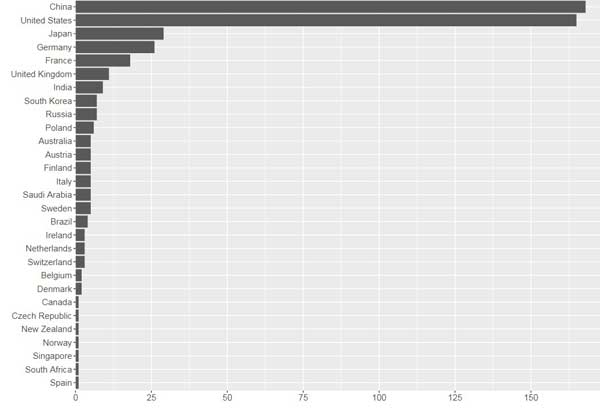
再往下的国家数字就很少了,日本35台,德国20台,法国18台,英国15台……这就是当今全球顶尖科技与商业的竞逐写照:只有中美两个大玩家。
【请不要再用人手去类比了——G的十亿级领域】
在进一步介绍之前,很有必要科普衡量现代计算机性能的基本专业参数——每秒浮点运算次数(英文缩写:FLOPS)。否则,一味地还在采用“相当于全球70亿人手按多少百亿年计算器”,实在既不直观,也难比较。
从鼻祖ENIAC的300 FLOPS开始,计算机开始了指数化发展的历程。在英文词汇与缩写里,K是千,10的3次方;M是百万,10的6次方;G是十亿,10的9次方,以此进位。
在超级计算机(简称超算)首次被中国媒体报道的80年代中期,超级计算机的速度是1 GFLOPS量级,也就是每秒十亿次浮点运算。
1983年中国造出第一台银河一号巨型计算机,每秒运算一亿次以上,也就是0.1GFLOPS。而当年全球最快的美国克雷,则是八亿次,也就是0.8GFLOPS。
放在今天,这性能大概连块电子表都不如。

【千倍性能的超算,过十几年就还不如个人玩具——T的万亿级领域】
十五年后,到了90年代末期,个人电脑上的CPU开始出现1 GFLOPS的能力,而此时全球最快的超级计算机,性能已达到了1 TFLOPS以上——T是一万亿,10的12次方。
因此个人电脑与同时代专业超算的差距,是1000倍。

而再过十五年,2014年的个人电脑CPU就有0.6 TFLOPS的能力,现在2018年的顶级手机CPU,也具备了同样的水准。

绝大部分人都不会意识到,手上小小的智能手机,竟然堪比20年前极其庞大笨重的全球最强超算,而且体积重量也缩小了1000倍。

否则,还怎么玩微信、刷视频、打游戏,以及实时美颜?那都是以接近T级的计算能力,实时算出来的!

信息科技的指数化发展,创造了无与伦比的爆炸式进步,也推动了无法想象的社会形态变革。
所以TFLOPS(万亿),才应该是讨论现代计算机的起点。否则,数据后面所列的〇和亿太多,实在超出了普通人的理解力和想象力,也脱离当下的发展现实。
【同样的,专业超算要保持比个人玩具强1000倍——P的千万亿级领域】
而主要用于游戏的显卡,由于几百个运算单元并行处理的特性,性能增长还高出一个数量级。
以目前市场上最热销、最主流的NVIDIA GTX 1060游戏显卡为例,它的成品价格是2000多元人民币,游戏单精度计算能力是4.4 TFLOPS,比传统CPU高了约10倍。
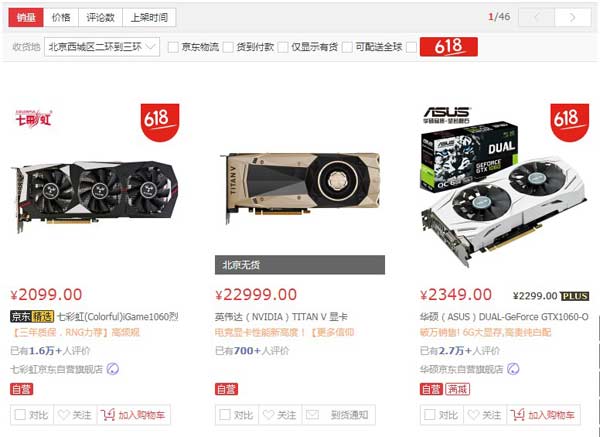
再往上,目前NVIDIA最新的顶级显卡Titan V达到了15 TFLOPS,是GTX 1060的三倍多,当然,售价也达到了两万多元。

而当TFLOPS再增长1000倍,就是PFLOPS(千万亿)。这才是当今专业超算的能力范畴——实际1个PFLOPS能力的超算,在去年底的榜单上,能排在全球183位。

【美国怎么夺回冠军的:等了整整3年】
为了夺回被中国占据的最快超算王座,早在2015年,IBM和NVIDIA就接下了美国政府的订单,要为掌管研制核武器的美国能源部所属的橡树岭国家实验室、劳伦斯利福摩尔国家实验室,分别打造20亿亿次和15亿亿次,也就是200 FLOPS和150 PFLOPS的超算。

两台超算分别命名为Summit和Sierra,总耗资约3.8亿美元。但一直要到2017年底,两家公司研制出相关核心芯片之后,才能转换为工程现实。
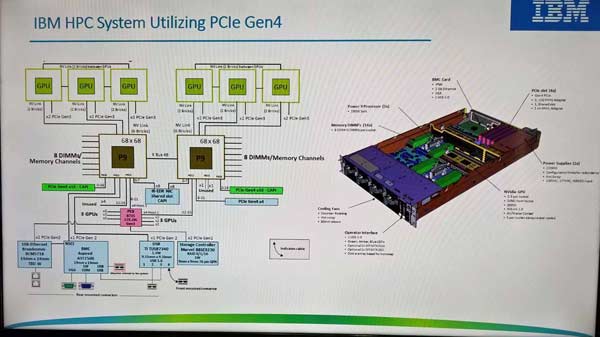
橡树岭国家实验室名为“顶点”(Summit)的超算,使用了4608个计算服务器节点,每个节点含有2个IBM的Power 9处理器(CPU)和6个NVIDIA(英伟达)公司生产的Tesla V100图形处理单元加速器(GPU),以及512 GB的DDR4 内存。采用效率更高的水冷散热。

NVIDIA的Tesla V100,采用台积电12纳米工艺制造,集成了210亿个晶体管,外围是32 GB内存。每个售价9000美元。
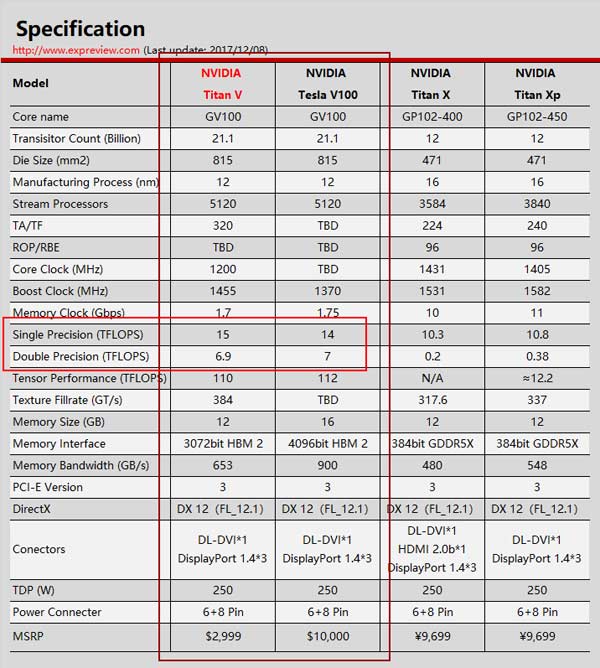
Tesla V100和民用顶级显卡Titan V同为Volta 架构,但考虑稳定性频率略低,理论计算能力为单精度14 TFLOPS,但科学计算都用双精度模式,为7 TFLOPS。

GPU接管了大部分的工作负载,但CPU仍然是数据处理的中心。IBM的POWER9,采用格罗方德(原AMD的制造部分)的14纳米工艺制造,集成了拥有80亿个晶体管。具有24核96个线程,实际使用22核。每颗售价6000美元起。

这样,单个节点拥有6块双精度7 TFLOPS的V100,理论计算能力就超过42 TFLOPS。4608个节点合起来,就是20万个TFLOPS,200个PFLOPS——用中文说就是20亿亿次。

这相当于个人电脑中高端游戏显卡的9万倍,主流CPU的90万倍。也比美国目前排名世界第五的的最强系统‘泰坦’(Titan)强8倍。
当然,比起个人电脑,一要解决大规模集成与互联并行计算,二要解决超大数据量吞吐与节点间交换,三要追求更高的效率和更高的功耗比,这就需要最先进的配件。
【只花了2亿美元?背后是几十亿美元的研制经费】
单算比例分摊,Summit的造价的确是2亿美元出头,看似并不多,在中国也就能修一公里多地铁,在美国连毛都不算。
但是,光TESLA V100及其背后的Volta 架构,就凝聚了Nvidia 7000 多名工程师超过3 年的研发,投入资金达30 亿美元。IBM的Power 9以及总体架构设计也要花差不多同样的钱。
IBM的女CEO罗睿兰(Ginni Rometty)表示:“这是我们最大的成就之一,它是最快、最智能的超级计算机。”
美国能源部长里克•佩里自豪地表示:“Summit的发布体现了美国在科学创新和技术开发方面的领导实力。它将对能源研究、科学发现、经济竞争力和国家安全有深远影响。”

【憋了5年美国超算重新超越中国,但也许只能秀半年】
另外,Summit的理论总计算能力是200 PFLOPS,也就是20亿亿次。但实测的真实计算能力还未公布,因为理论加总的总和本无法全部兑现。

中国的神威-太湖之光,理论能力125 PFLOPS,实测对兑现了93 PFLOPS,效率近75%,已经是很高的记录了。
美国之前排名第三、全球第七,能源部洛斯阿拉莫斯国家实验室的Trinity,实测效率不到32%。可见系统架构设计有问题。

美国虽然能借Summit 重回超算榜首地位,但这个宝座恐怕坐不了多久,根据中国最新的进展,恐怕到年底,中国超算就有望重新取而代之。
想必,中国超算的最新进展及其应用场景,才是广大读者真正更关心的话题。请待下篇。
凤凰新闻客户端主笔 唐驳虎




