原标题:论文造假被AI抓 机器学习检测出4000多论文造假
新智元报道
编辑:克雷格、三石
【新智元导读】在生物医学领域的论文中,AI已经搜索出9%的高度重复图像,0.59%的论文被认为存在欺诈嫌疑。因图像造假撤回的医学论文,一年时间可能浪费接近10亿美元的研发成本。
“打击论文造假,维护科研正义”。这不是一句喊口号的话。
今年6月,斯坦福大学微生物学家分析了2009-2016年发表在分子与细胞生物学(MCB)上的960篇论文,发现其中59篇(6.1%)含有“不适当的”重复图像,约有2%值得再去进行图像证伪。
不过,斯坦福大学微生物学家的工作完全依靠手动,五位研究人员靠十只手从近1000篇论文里总结出了这一成果。
现在,AI的介入让论文中的可疑图像被发现的概率大大提升,一个显著的成果是,在生物医学领域的论文中,AI已经搜索出9%的图像是高度重复的,0.59%的论文被认为存在欺诈嫌疑。
用AI打击论文图像造假,仍有4000多篇医学“问题论文”
使用AI来打击论文图像造假的工作是由纽约雪城大学(Syracuse University)机器学习研究员开发算法,他们分析了PubMed Open Access子集(PMOS)中截止到2015年发布的所有数据,包含了760036篇文章、超过200万的数据。
研究人员构建了一个pipeline,以自动检测不适合图像重用候选对象,在初步检测之后,删除了可能只是文本的图像或表示为图像的方程式,留下了大约200万张图片。
接着,研究人员发现每张图像平均有大约1K高熵关键点,这产生了大的相似度检测问题,研究人员使用近似最近邻算法来解决这个问题。之后,机器学习算法来估计是否显示生物图像。
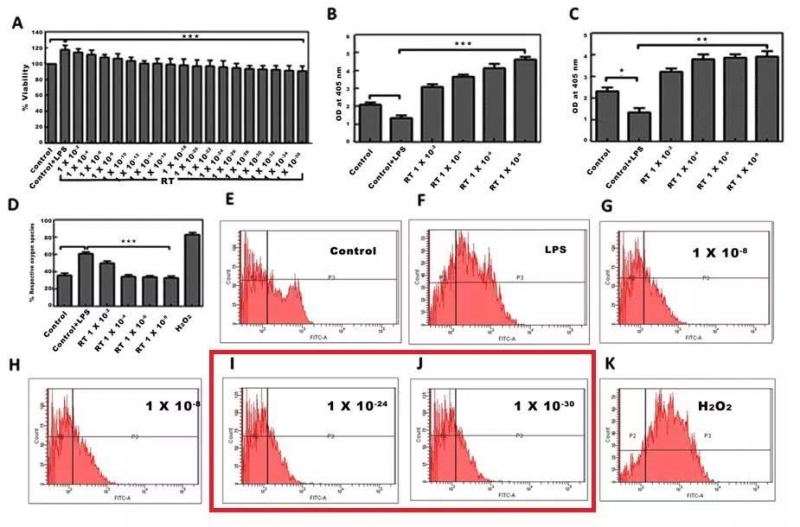
检测复制-移动重用。A.癌变细胞和缩小部分的原始例子。B.关键点(高熵区域)的计算C.最近邻匹配。D.集群关键点、跨集群匹配和仿射变换。
最后,使用人工来评估不当重用。
算法检测图像区域重用,同时对旋转、裁剪、调整大小和对比度变化具有鲁棒性。总的来说,这项研究得出一个结论:在PubMed Open Access上,大约有0.59%的文章会被一致认为是具有欺骗性的。也就是说,在760036篇文章里面,大约有4484篇文章涉嫌造假。
论文图像篡改可能导致一年损失10亿美元
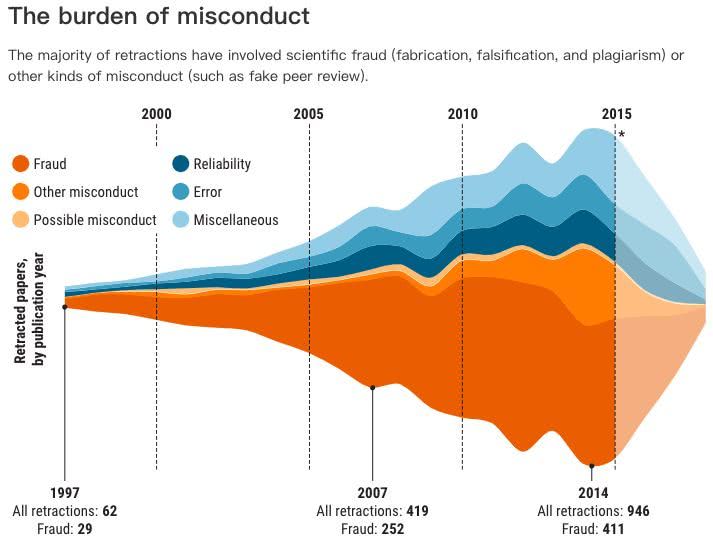
学术研究论文中的图像造假的祸害十分普遍。
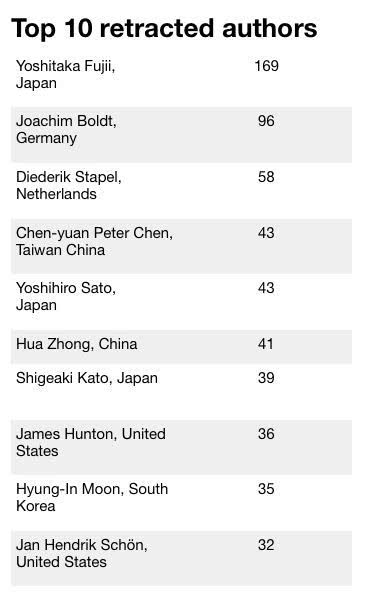
两个星期前,Science联合撤稿观察发布了一个“撤稿”报告,许多数字令人震惊:过去10年里学术期刊撤回的论文数量增加了10倍,撤稿率最高的国家中国排第7,撤稿最多的10位作者中,中国占了两人。
Top 10撤稿作者(数据来自Science)
在撤稿观察的数据库中,有18000份研究论文被撤回(最早可追溯到20世纪70年代),其中,317篇被撤回论文进行了图像篡改,约占整体论文的1.7%。
宾夕法尼亚大学生物工程副教授Arjun Raj早在2012年就指出,平均一篇生物医学研究论文背后的科学成本约为30万美元至50万美元。而柳叶刀报道称,美国研究人员在当年发表了近152000篇论文。
这样推算,即使每篇论文成本30万美元,美国研究人员在2012年发表的所有生物医学科学论文的成本也将接近500亿美元。
如果2%的论文因为图像伪造需要撤回,美国可能会在2012年浪费接近10亿美元。随着全球科学产量每九年翻一番,照此计算,自2012年以来,因撤稿产生的负利润率可能会更大。
图像篡改向来如此糟糕吗?
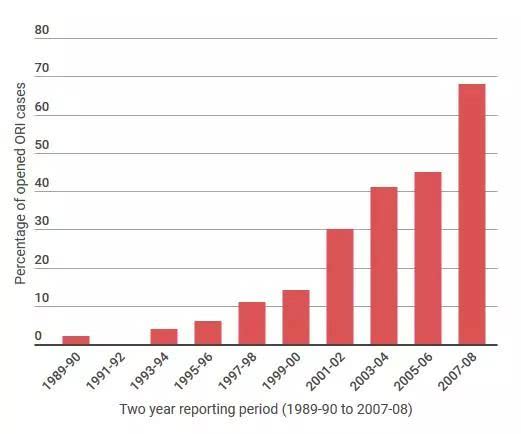
有些研究人员认为,这么多年来,论文图像篡改问题一直在恶化。
来自美国研究诚信办公室(the United States Office of Research Integrity,ORI)的数据表明,在Photoshop发布后,他们所处理的涉及图像处理的案件比例有所增加。
技术在打击论文造假的过程中,一直是一场“猫鼠游戏”。AI除了检测图像区域重用,也成为对抗Photoshop的利器。
今年9月,Scientific Reports发表了一篇论文,文章指出,基于植物Rhus toxicondendron (毒性常春藤)的稀释度非常高的顺势疗法,至少与减轻疼痛的药物(加巴喷丁)一样有效。
不过,很快这篇介绍顺势疗法的论文,被生物学家Enrico Bucci使用的一款软件标记出来错误:在两种不同的实验中,所建议的药物浓度差别很大,而其图表却惊人地一致。
后来,论文作者回应称,他的的团队在准备手稿时犯了一些无意的错误,导致重复的图像和重复的数据。
作者表示,文本和数字之间的差异是错别字的结果。该小组将要求Scientific Reports更新该文章并进行更正。但也表示,“这不会以任何方式改变科学结论”。
AI距离自动打击论文造假还有多远?
然而,即使基于软件的方法已经被广泛讨论了近十年,使用此类应用程序的公司还是很少用软件发布他们的结果。
基于软件的方法仍然需要人为的监督支持。检测图像处理软件的开发有可能增加扫描图像期刊的数量。然而,需要注意的是,软件的使用并不能消除对人为干预的需求。软件的输出必须由人来评估。
一个领域是软件开发有可能对大型文章数据库的图像复制检测产生巨大影响,使用视觉检查技术不可能进行这种大规模的比较。
AI来检测论文图像造假在未来可能有两种形式。一是,公司可以为期刊编辑提供定制的应用程序,然后编辑可以使用这些应用程序对即将发表的论文进行分析,这可能类似于反抄袭软件的工作方式。
而另一种方法是,图像完整性分析公司将自己的人力和计算机资源分配给期刊进行图像完整性检查。
随着自动化的图像分析软件演变为一个企业,那些造假的研究人员可能会发现他们的计量很难再“瞒天过海”。然后,也许会出现另一个更为复杂的工具,使得造假的图像更难以被发现,这场“猫鼠游戏”更能还将继续。