原标题:语音翻译也能端到端 深度学习这条路有戏
新智元报道
来源:科大讯飞
编辑:文强
【新智元导读】科大讯飞日前在全球最具影响力的口语机器翻译评测比赛IWSLT中,获得了语音翻译端到端模型评测的冠军,还成为英德口语翻译任务中唯一受邀做Oral report的参赛团队。端到端技术是当前语音翻译的研究前沿,科大讯飞联合优化语音识别和机器翻译的新技术路线,理论上更具前景,一旦技术研究成功,将为翻译机器性能的提升带来极大促进。
提问:语音翻译涉及哪些步骤?
你或许会说,语音识别和机器翻译——没错,传统的语音翻译通常采用语音识别和机器翻译级联的方式实现,对输入语音先进行语音识别得到文本结果,然后再基于文本进行机器翻译,这也是当前语音翻译采用的主流方法。
不过,由于口语句子中含有大量非规范语言现象,例如重复、省略、颠倒,以及语义逻辑不清,断句困难等问题,导致后续机器翻译带来严重的挑战。此外,复杂环境下语音识别受发音人口音、环境噪声,以及和语言中存在的同音词、易混淆词等复杂音素的影响也存在着识别错误,对最终机器翻译性能也可能带来影响。
因此,实际应用系统中,通常会在语音识别和机器翻译之间增加一个语音识别后处理模块,通过对识别结果进行规整、断句、顺滑、标点预测,甚至纠错来尽可能地减小口语化和识别错误的影响。
不过,受语音和语言复杂性的影响,截止到目前为止,这些问题并没有被真正解决。
在刚刚结束的2018年国际口语机器翻译评测比赛(International Workshop on Spoken Language Translation,IWSLT)中,科大讯飞团队在端到端模型(End-to-End Model)的评测比赛中,以显著优势夺得第一名。该奖项也是科大讯飞今年在各项国际竞赛中的第9个“世界冠军”。
端到端语音翻译技术路线,是通过构造一个完整的神经网络模型,联合优化语音识别、识别后处理和机器翻译,建立源语言语音信号到目标语言文字的映射关系,进而实现从原始语音到目标译文的翻译。
这提供了一种解决语音翻译的新思路,而且从目前看是初步可行的。一旦技术研究成功,理论上可以让语音翻译更准更快,未来也将为翻译机器性能的提升带来极大促进。
国际顶级口语机器翻译评测比赛 IWSLT,推动语音翻译新方向
IWSLT是国际上最具影响力的口语机器翻译评测比赛之一,重点关注口语,实现语音到文本的翻译,从而解决人和人交流的问题。
到目前为止,IWSLT已经举办了15届,吸引了全球70多家科研团队的参与。IWSLT针对语音翻译实际应用面临的难题,通过每年设定一些研究任务,并向外界提供公开的数据集合和评测交流机会,吸引了来自全球的科研团队参与,对于推动语音翻译技术创新和知识共享具有重要的意义。
除了科大讯飞,IWSLT 2018吸引了世界各地多所机器翻译领域的知名大学及研究所参加,包括英国爱丁堡大学(University of Edinburgh)、美国约翰霍普金斯大学(JHU)、德国卡尔斯鲁厄理工学院(KIT)、意大利Bruno Kessler 基金会(FBK)、芬兰赫尔辛基大学(Helsinki),以及国内的阿里巴巴、搜狗等。
本次比赛包括两个主要任务,一是英语到德语演讲场景下的语音翻译任务;二是巴斯克语到英语的低资源文本翻译任务。
其中,在英语到德语的语音翻译任务上,主办方在今年提出了两种评测方案:
端到端模型是当前口语翻译研究领域的前沿,随着深度学习的进步,研究人员开始探索通过构造一个完整的神经网络模型,建立语音信号到目标文字的映射关系。
该方法通过将语音识别、识别后处理和机器翻译统一起来联合优化,为解决传统级联方案分而治之中存在的难题提供了一种新的思路。例如,2017年Interspeech会议上,谷歌研究人员就将该方法应用到西班牙到英语的语音翻译任务上,取得初步成效。
引入这一新的评测方案,也体现了IWSLT主办方引导科研探索,推动语音翻译技术不断进步的努力。
科大讯飞勇于挑战新路线,端到端语音翻译获得第一
科大讯飞参与了口语翻译的两种评测,并且是唯一参与端到端模型这种新技术路线的中国团队。不仅如此,科大讯飞还作为唯一受组委会邀请的语音翻译任务参赛团队、进行Oral report,向与会人员分享两种技术路线研究所采用的方法,对促进语音翻译新技术的进步具有重要作用。
因为语言和语音本身的复杂性,新技术路线对统一建模需要很强的语音处理能力和调序能力,加之语言本身受到口语表达、环境噪声的干扰,所以端到端技术路线要实现从原始语音到目标文本的翻译,就是难上加难。
值得一提,赛事提供的公开数据集合中,能够为端到端模型方法提供直接的有监督数据是小规模的。要在3个月的时间里,在小规模数据上构建一套高性能的端到端语音翻译系统,非常具有挑战性。
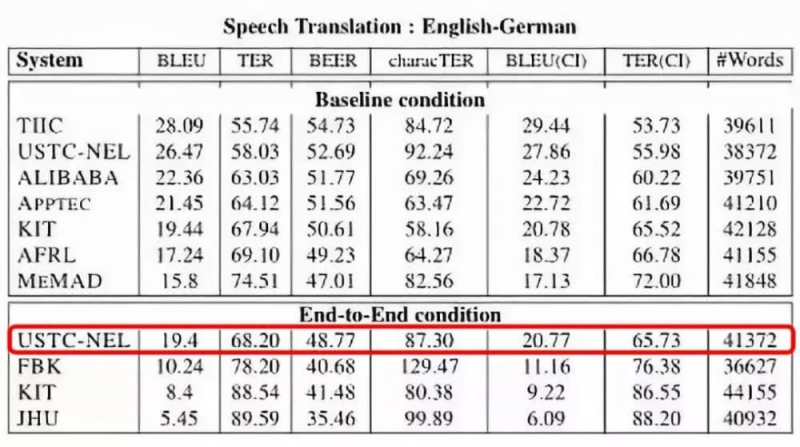
基于语音和机器翻译上雄厚的技术积累,讯飞研究团队针对端到端语音翻译任务开展了探索性研究,最终在英德语音翻译任务的端到端模型评测方案上获得了第一名(与第二名BLEU分数拉开9个百分点,一般而言,提升3个百分点就能明显体会到系统的优劣差异)。
不仅如此,在基线模型评测中,科大讯飞也取得了第二名的好成绩。
“比赛的成绩只是一方面,我们看重的是在源头技术、新技术上进行探索,”科大讯飞的研究人员表示。
“我们参加了本次IWSLT评测的语音翻译任务,在基于传统的基线模型中,针对语音识别文本结果和机器翻译训练数据源语言文本风格不匹配问题,提出了对源语言文本逆变换以适配识别风格的方法,提高了语音翻译的鲁棒性。在端到端模型中,提出了基于DenseNet和BiLSTM编码,以及基于自注意力机制解码的端到端建模方案。实验结果表明,尽管当前端到端模型的效果低于传统方法,但从结果来看也证明该方法具有一定的可行性,整体系统框架也更加简洁优雅,有望为语音翻译提供一种新的解决思路。”
客观评价语音翻译端到端技术,数据将是一大瓶颈和障碍,因为语音识别的数据已积累了上十万小时、机器翻译的数据搜集也达到千万甚至上亿,但端到端的模型,需要专门的语音到文本的句对,这方面的数据目前积累不够,若要商业化,还需要更大的数据支撑。
对此,科大讯飞研究团队表示,“由于语音翻译任务的复杂性以及训练数据搜集的困难,无论传统的基线模型方案还是最新提出的端到端语音翻译方案,在实际应用中都还面临一系列的难题,需要学术界和产业界共同努力。”
至于端到端的新技术,“如果能减少对有监督语音翻译平行数据的依赖那是最好不过,而且这存在一定的可能性,例如可以尝试借用现有的语音识别训练数据和机器翻译训练数据,我们正在努力探索。”